Workers
Worker
Example of a local model service running models through arcadia to drive rapid deployment of various fastchat-based model services.Worker resource is defined:
// WorkerSpec defines the desired state of Worker
type WorkerSpec struct {
CommonSpec `json:",inline"`
// Normal worker or vLLM Worker(inference acceleration)
Type WorkerType `json:"type,omitempty"`
// Model this worker wants to use
Model *TypedObjectReference `json:"model"`
// Resource request&limits including
// - CPU or GPU
// - Memory
Resources corev1.ResourceRequirements `json:"resources,omitempty"`
// Storage claimed to store model files
Storage *corev1.PersistentVolumeClaimSpec `json:"storage,omitempty"`
}
// WorkerStatus defines the observed state of Worker
type WorkerStatus struct {
// PodStatus is the observed stated of Worker pod
// +optional
PodStatus corev1.PodStatus `json:"podStatus,omitempty"`
// ConditionedStatus is the current status
ConditionedStatus `json:",inline"`
}
Spec Field Details
- CommonSpec: Basic descriptive information
- Type: Type of model worker node, currently classified as:
- fastchat
- fastchat-vllm
- Model: The CR of the model run by the model worker node, which records the storage information of the model and is used to load the model file when the model is deployed.
- Resource: The resources requested by the model worker node when it is running, including:
- CPU
- Memory
- GPU: "nvidia.com/gpu: "1" # request 1 GPU"
- Storage: Requested persistent storage (If it is empty, emptydir is used by default to share data within the pod)
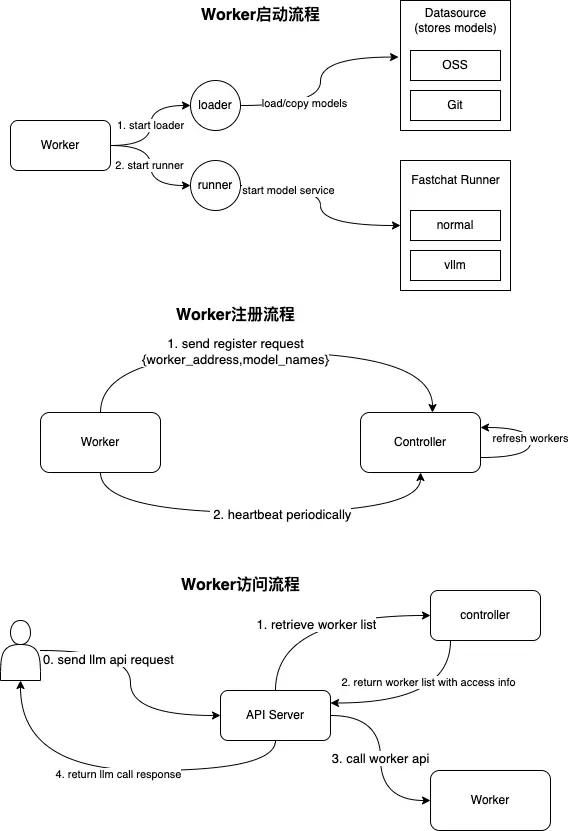
Worker startup process, registration session, and invocation process are illustrated in the following figure:
Recommended Hardware Resource Requirements for Worker Nodes
-
CPU
- Inference without CPU:2 cores or more recommended
- Use CPU inference for Embedding models:
- Lite/Small level models (~300 MB): 4+ cores recommended
- General and Large models (700~1.5GB, e.g. bge-large-en-v1.5): 6+ cores recommended
- Larger models (>2GB, e.g. bge-m3): 8+ cores recommended, or use GPU instead
- Large models using CPU inference:16 cores or more are recommended
- It is more efficient to use a CPU that doesn't support the AVX-512 instruction set
- CPUs are less efficient at inference of large models, requirements are for reference only
-
Memory
- Inference without CPU:2GB or more recommended
- Use CPU for inference on Embedding models:
- Lite/Small level models (~300 MB):3GB or more are recommended
- General and Large models (700~1.5GB, e.g. bge-large-en-v1.5): 4GB or more are recommended
- Larger models (>2GB, e.g. bge-m3): 8GB or more are recommended, or use GPU with similar size VRAM instead
- Use CPU for inference on large models:
- Depending on the model size, the amount of memory used is roughly equivalent to the amount of graphics memory used by the model when inferring on a graphics card.
- CPU inference for large models is less efficient, and CPU usually does not support int8/int4 quantisation, so requirements are for reference only.
-
GPU
- Recommended GPUs for NVIDIA Turing architecture and newer
- RTX 20 series and newer graphics cards; Tesla T4 and newer accelerator cards
- Memory Requirements
- Ratio of memory usage per 1B parameter (estimated)
- float32:4GB
- fp16/bf16:2GB —— Default options for most unquantified models
- int8:1G
- int4:0.5G
- Minimum Memory Requirement = Number of Gamers × Ratio × 1.25, the reserve ratio fluctuates depending on the model
- For example:
- ChatGLM3-6B: 6 × 2 × 1.25 = 15 GB;official requirements > 13GB
- Qwen-72B-int4:72 × 0.5 × 1.25 = 45 GB;official requirements > 48GB
- Ratio of memory usage per 1B parameter (estimated)
- Actual test results:
- Recommended GPUs for NVIDIA Turing architecture and newer
| Model Name | Actual GPU Memory Usage | Recommended GPU Memory | Reference GPU Configurations |
|---|---|---|---|
| ChatGLM2-6B | 13 GB(fp16) | >= 16GB | 1 * Tesla T4 16GB 1 * RTX 4080 16GB 1 * RTX A4000 16GB |
| 77B Level Models (e.g. Qwen-7B, Baichuan2-7B) Qwen-7B,Baichuan2-7B) | 15 GB(fp16) | >= 20GB (T4 GPU inference may be unstable) | 1 * RTX 3090 24GB 1 * RTX 4000 Ada 20GB 1 * RTX A5000 24GB |
| 13B Level Models (e.g. Qwen-13B) | 28 GB(fp16) | >= 32GB | 2 * Tesla T4 16GB 1 * V100 32GB |
| 70B Level Models (e.g. Qwen-72B) | ~150 GB(fp16) | >= 160GB | 8 * RTX 3090 24GB 5 * V100 32GB 2 * A100 80GB |