Datasets and VersionedDatasets
Datasets is unified management of available data, including training data sets, knowledge base data sets, etc. Supports independent version iteration, data viewing, and data update.
Introduction
The datasets represent a set of files with relevant attributes that are managed by the user. These files are processed in the same way and used for subsequent model training, knowledge base and other data management.
Related Features
- Supports multiple types of data:
- Text
- Images
- Videos
- A single dataset is only allowed to contain files of the same type, different types of files will be ignored.
- Multiple versions of the datasets are allowed, and data processing is performed for a single version.
- After a version of a dataset has completed its data processing, the data processing service needs to store the processed storage back into
VersionedDatasets.
Resource Abstraction
To implement dataset management capabilities, two Custom Resource Definitions (CRDs) are used:
- CRD Dataset: defines dataset global parameters, including:
- Dataset data type
- Application scenario
- Creator
- Display name
- CRD VersionedDataset: defines the parameters related to versions, including:
- Dataset
- Version number
- List of files managed under the versioned dataset
The dataset data is stored in the system data source, and the storage structure is as follows:
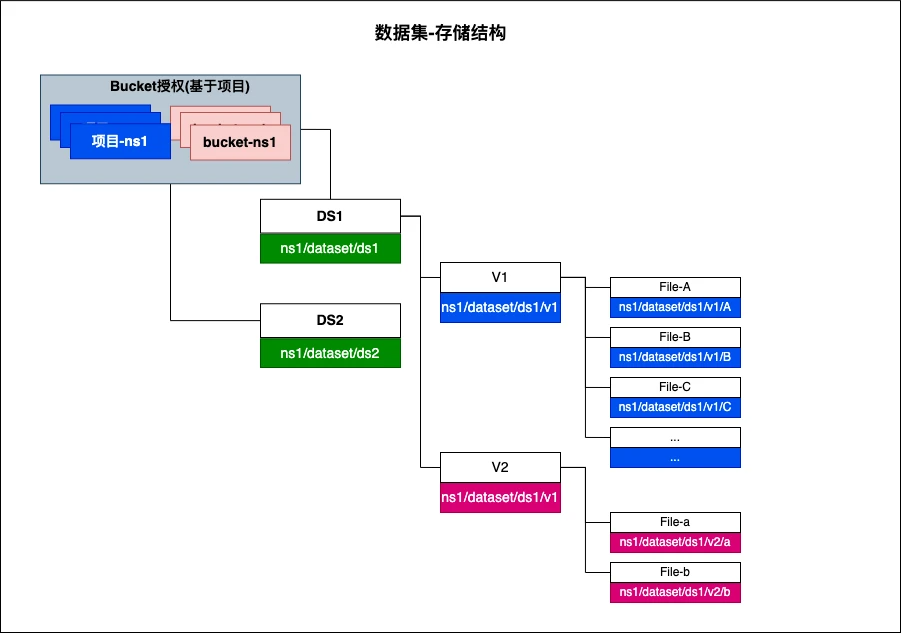
Function Implementation
File Upload
File upload consists of 4 steps:
- Call get_chunks to retrieve the already uploaded chunks. If it's a new file, the returned uploadid will be an empty string. Otherwise, it will have a value. If the uploadid is empty from the first step, call new_multipart to obtain a new uploadid.
- Use the obtained uploadid to call get_multipart_url and retrieve the upload URL for each chunk. After getting the url, directly PUT, the body is the content of the file to upload.
- After each chunk is uploaded, call complete_multipart to let the backend finish merging the chunks.
- Call update_chunk to update the upload progress stored in the backend.