Workers
Worker
通过 arcadia 来运行模型的本地模型服务示例,用来驱动��基于 fastchat 的各类模型服务的快速部署。Worker 资源定义:
// WorkerSpec defines the desired state of Worker
type WorkerSpec struct {
CommonSpec `json:",inline"`
// Normal worker or vLLM Worker(inference acceleration)
Type WorkerType `json:"type,omitempty"`
// Model this worker wants to use
Model *TypedObjectReference `json:"model"`
// Resource request&limits including
// - CPU or GPU
// - Memory
Resources corev1.ResourceRequirements `json:"resources,omitempty"`
// Storage claimed to store model files
Storage *corev1.PersistentVolumeClaimSpec `json:"storage,omitempty"`
}
// WorkerStatus defines the observed state of Worker
type WorkerStatus struct {
// PodStatus is the observed stated of Worker pod
// +optional
PodStatus corev1.PodStatus `json:"podStatus,omitempty"`
// ConditionedStatus is the current status
ConditionedStatus `json:",inline"`
}
Spec字段详解
- CommonSpec: 基础的描述性信息
- Type: 模型工作节点的类型,目前分为:
- fastchat
- fastchat-vllm
- Model: 模型工作节点运行的模型对应的 CR。模型 CR 中记录模型的存储信息,用于后续模型部署时加载模型文件使用
- Resource: 模型工作节点运行时申请的资源,包括:
- CPU
- Memory
- GPU: "nvidia.com/gpu: "1" # request 1 GPU"
- Storage: 申请的持久化存储(如果为空,默认采用 emptydir 在 pod 内部共享数据)
Worker 的启动流程、注册会话、调用流程参考下图示意:
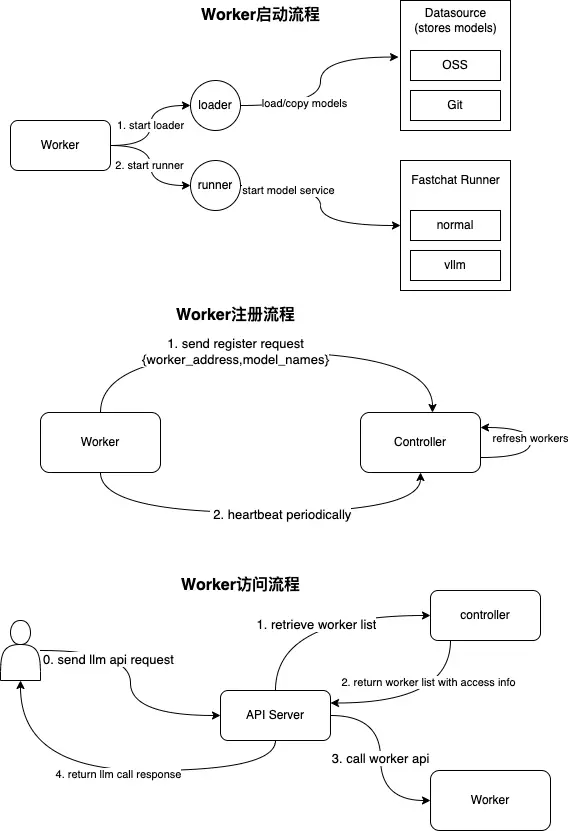
Worker 节点推荐硬件资源要求
-
CPU
- 不使用 CPU 推理:建议 2 核以上
- 使用 CPU 推理 Embedding 模型:
- Lite/Small 级模型(~300 MB):建议 4 核以上
- 一般及 Large 模型(700~1.5GB):建议 8 核以上
- 使用 CPU 推理大模型:建议 16 核以上;
- 使用支持 AVX-512 指令集的 CPU 效率更高;
- CPU 推理大模型效率较为低下,仅供参考
-
内存
- 不使用 CPU 推理:建议 2GB 以上
- 使用 CPU 推理 Embedding 模型:
- Lite/Small 级模型(~300 MB):建议 4GB 以上
- 一般模型(~700 MB):建议 6GB 以上
- Large 类模型(~1.5GB):建议 8GB 以上
- 使用 CPU 推理大模型:
- 视模型规模而定,内存占用量与该模型在显卡上推理时占用的显存量基本相当
- CPU 推理大模型效率较为低下,且 CPU 通常不支持 int8/int4 量化,因此仅供参考
-
GPU
- 建议使用英伟达 Turing 架构及更新的 GPU
- RTX 20 系列及更新的显卡;Tesla T4 及更新的加速卡
- 显存要求
- 每 1B 参数对应的显存占用比例(估算)
- float32:4GB
- fp16/bf16:2GB —— 大多数无量化模型默认选项
- int8:1G
- int4:0.5G
- 最低显存需求 = 参数量 × 比例 × 1.25,预留比例随模型不同有浮动
- 例:
- ChatGLM3-6B: 6 × 2 × 1.25 = 15 GB;官方要求 > 13GB
- Qwen-72B-int4:72 × 0.5 × 1.25 = 45 GB;官方要求 > 48GB
- 每 1B 参数对应的显存占用比例(估算)
- 实际测试结果:
- 建议使用英伟达 Turing 架构及更新的 GPU
| 模型名称 | 实际显存占用 | 建议显存 | 参考显卡配置 |
|---|---|---|---|
| ChatGLM2-6B | 13 GB(fp16) | >= 16GB | 1 * Tesla T4 16GB 1 * RTX 4080 16GB 1 * RTX A4000 16GB |
| 7B 级模型 (如 Qwen-7B,Baichuan2-7B) | 15 GB(fp16) | >= 20GB (T4 显卡推理不稳定) | 1 * RTX 3090 24GB 1 * RTX 4000 Ada 20GB 1 * RTX A5000 24GB |
| 13B 级模型 (如 Qwen-13B) | 28 GB(fp16) | >= 32GB | 2 * Tesla T4 16GB 1 * V100 32GB |
| 70B 级模型 (如 Qwen-72B) | ~150 GB(fp16) | >= 160GB | 8 * RTX 3090 24GB 5 * V100 32GB 2 * A100 80GB |