Introduction
Introduction to KubeAGI
KubeAGI is a simple, diverse and secure one-stop LLMOps platform designed to help everyone find a more perfect blend of human and AI. It provides a complete development platform for enterprise developers through data management, data processing, knowledge base construction, model association and model application construction. Lowering the threshold of use, users with no development background can quickly build their own big model applications out-of-the-box with the KubeAGI platform.
Key Concepts
| Concept | Description |
|---|---|
| Dataset | Data forms the foundation for model training and knowledge base application building. The quality of data significantly impacts the effectiveness of the entire model. The platform provides dataset management functionalities, allowing centralized management of dispersed data. It supports version control of datasets and standardizes data management, thereby reducing the cost of data collection and management. |
| Model | Usually refers to advanced algorithms and mathematical frameworks used for processing and understanding complex data. |
| LLM | Large Language Model, a deep learning-based model specifically designed for processing, understanding, and generating natural language. |
| Text Embedding | Text embedding models are techniques used to convert text (such as words, phrases, or sentences) into numerical vectors. |
| Vector | A vector can be understood as an array of numbers. The similarity between two vectors can be calculated using mathematical formulas, where a smaller distance indicates a higher similarity between the vectors. Vectors can be applied to various media such as text, images, and videos to measure their similarity. |
| Prompt | A prompt is a simple instruction given to a large model. It can be a question, a text description, or even a text description with a set of parameters. The large model generates corresponding text or images based on the information provided by the prompt. |
For more concepts, you can refer to the Common Terms and Parameters in the AGI Field.
Core Functions
| Category | Function Module | Function Description |
| Data Management | Dataset Management | Includes: list, create new datasets, datasets details, delete datasets and other functions, including datasets contain multiple versions of management |
| Data Processing | Provides data processing capabilities, including functionalities such as listing tasks, creating new tasks, viewing task details, and deleting tasks. Tasks support features like abnormal data cleansing and data privacy processing. | |
| Knowledge Base Management | Includes: list, create new knowledge bases, view knowledge base details, and delete knowledge bases and other functions. | |
| Model Management | Model Repository | Includes: list, create new models, view model details, and delete models and other functions, where the model contains multi-version management. |
| Model Service | Includes: list, create new model service, model service details, delete model service and other functions. | |
| Application Management | Model Application | Build your own large model applications, such as interacting with LLM applications through conversations, subscribing to real-time data, and improving the real-time information of large models. |
KubeAGI Advantages
- One-stop platform with comprehensive processes The KubeAGI platform includes data management, model management, application building, and dialogue boxes that allow developers to manage the full lifecycle of their models through a visual interface without the need for additional tools.
- Easy to use The KubeAGI platform has a low technical barrier, built-in common models, and is ready to use out-of-the-box. Users can easily get started and obtain high-performance model applications through a small amount of data manipulation.
- Security and reliability The KubeAGI platform provides data cleansing capabilities, and filters sensitive data, private data, etc. to ensure that the inference content is safe and reliable.
Application Scenarios
KubeAGI provides different functional services for different enterprise needs.
- Dialogue and Communication In real life, KubeAGI provides fast response to user needs, accurately matches user needs, completes marketing, timely response, positive psychological counselling, etc., and improves customer experience.
- Industry Knowledge Base A knowledge base is a repository of knowledge and information based on cloud computing, including documents, images, videos, and other multimedia resources. KubeAGI can be applied to the construction and management of knowledge bases in various industries, providing more intelligent and personalized knowledge services.
- Enterprise Assistant Enterprise Assistant supports users to retrieve internal information, such as enterprise rules and regulations, enterprise product information, enterprise customer information and so on.
- Content Creation AGI can automatically analyse and generate various types of documents, such as reports, contracts, manuals, etc. through natural language processing, machine learning and deep learning technologies. Intelligent document generation can improve the efficiency, accuracy and personalisation of document generation.
Knowledge Base Structure
- Vector If we directly pass a piece of text to the computer, the computer can not be directly understood, vector is the computer to understand the two pieces of text whether there is a similarity, relevance of one of the ways, because the vector can be converted into a language that the computer can understand. Vector can be simply understood as an array of numbers, the distance between two vectors can be derived through a mathematical formula, the smaller the distance represents the greater the similarity of the two vectors. From there, it is mapped to media such as text, images, videos, etc. and can be used to determine the similarity between two media. And since text is of multiple types and has thousands of combinations, it is difficult to guarantee its accuracy when converted into vectors for similarity matching. In the knowledge base constructed by the vector scheme, topk recall is usually used, that is, to find the first k most similar contents, which are thrown to the big model to do further semantic judgement, logical reasoning and summarisation, so as to realise the knowledge base Q&A. Therefore, in knowledge base Q&A, the vector search aspect is the most important. There are many factors affecting the accuracy of vector search, mainly including: the quality of the vector model, the quality of the data (length, completeness, diversity), and the accuracy of the searcher (the trade-off between speed and accuracy). Corresponding to the quality of the data is the quality of the search terms.
KubeAGI Knowledge Base Principles
Split the text content into QA and use only Q to do vector matching with user input, which makes the retrieved content more accurate. When generating Q&A pairs, the user can manually select the model, GPT 3.5 is just an example.
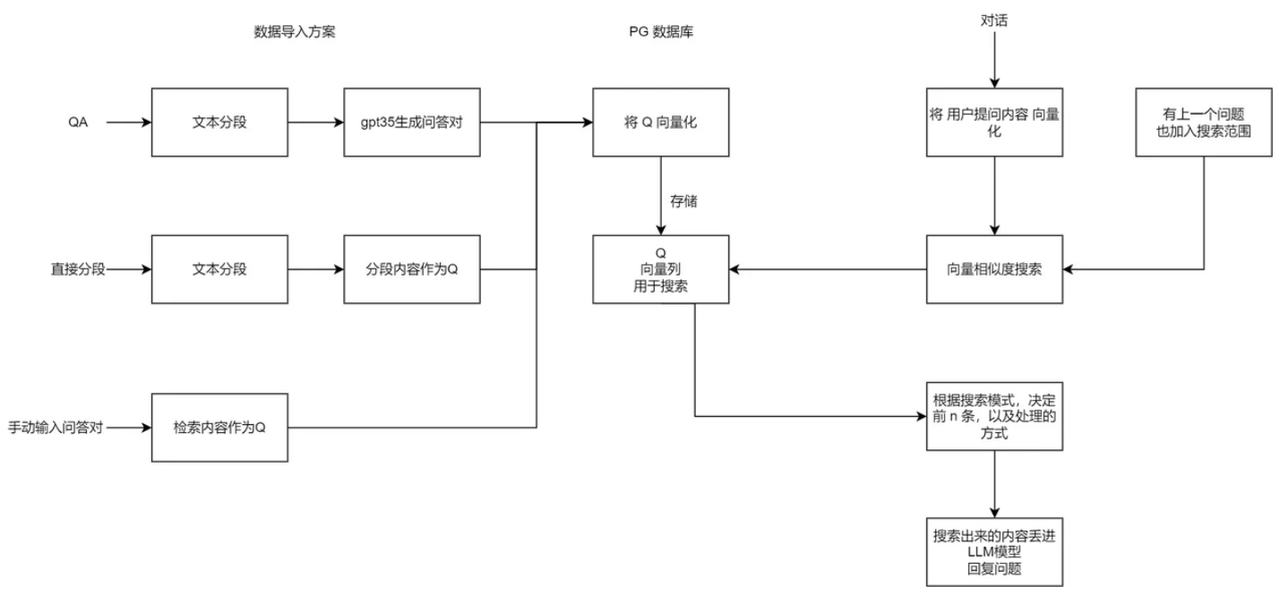
Methods to Improve Search Accuracy
- Better Segmentation Segmentation: when the structure and semantics of a passage are complete and singular, precision improves. Therefore, many systems optimise the segmenter to guarantee the integrity of each set of data as much as possible.
- Optimising search terms: In practice, user questions are usually vague or missing, and not necessarily complete and clear. Therefore, optimising the user's question (search term) can largely improve the accuracy as well.
- Fine-tuning the vector model: Since the vector models used directly in the market are general-purpose models, the retrieval accuracy in specific domains is not high, so fine-tuning the vector model can largely improve the retrieval results in specialised domains.
Description of Built-in Models
Model Categories
| Model Category | Description |
|---|---|
| LLM | Large Language Model |
| embedding | In the field of Natural Language Processing (NLP), embedding usually refers to the process of mapping words, phrases, or sentences to a low-dimensional vector space. It converts discrete symbols (such as words or characters) in the text into continuous and dense vector representations, which facilitates the comparison of semantic similarity. |
Built-in Base Models
| Base Model | Model Category | Model Description |
|---|---|---|
| baichuan2-7b | LLM & embedding | Baichuan 2.7b is a new generation of open-source large language model developed by Baichuan AI. It is trained on high-quality corpora with 26 trillion tokens and achieves leading performance on authoritative Chinese and English benchmarks of the same size. This version is a chat version with 7 billion parameters. |
| chatglm2-6b | LLM & embedding | Chatglm2-6b is a bilingual dialogue model released by Zhipu AI and Tsinghua KEG Lab. It has powerful inference performance, improved effectiveness, lower deployment threshold, and longer context. It shows significant performance improvement compared to the first generation on datasets such as MMLU and CEval. |
| qwen-7b-chat | LLM & embedding | Qwen is an open-source large language model series introduced by Alibaba Cloud. It covers multiple languages in training data (currently mainly Chinese and English) with a total volume of 30 trillion tokens. The Qwen series models have shown competitive performance in related benchmark evaluations, significantly surpassing models of the same scale and closely following a series of top closed-source models. Qwen-Chat has capabilities in chat, text creation, summarization, information extraction, translation, as well as some code generation and simple mathematical reasoning abilities. It is optimized for LLM integration with external systems and has strong tool invocation capabilities, as well as the ability to act as an agent in recent Code Interpreter scenarios. |
| llama2-7b | LLM & embedding | Developed and open-sourced by Meta AI, LLM is a 7B-parameter large language model that excels in scenarios such as coding, reasoning, and knowledge application. |
| m3e | embedding | M3E stands for Moka Massive Mixed Embedding. This model is trained, open-sourced, and evaluated by MokaAI. The training script uses "uniem," and the benchmark uses "MTEB-zh Massive." This model is trained on a large-scale dataset (over 22 million sentence pairs) for Chinese text. It supports homogeneous text similarity calculation and heterogeneous text retrieval for both Chinese and English. In the future, it will also support code retrieval embedding. This model is an embedding model that can convert natural language into dense vectors. |
| bge-large-zh | embedding | BGE-Large-ZH is a Chinese version of the text representation model developed by Zhiyuan Research Institute. It can map any text to a low-dimensional dense vector for tasks such as retrieval, classification, clustering, or semantic matching. It also supports the ability to call external knowledge for large models. |